
As you increase the size and complexity of your quantum simulation, you rapidly require a large increase in computational power. This guide describes considerations that can help you choose hardware for your simulation.
Your simulation setup depends on the following:
- Noise; noisy (realistic) simulations require more compute power than noiseless (idealised) simulations.
- Number of qubits.
- Circuit depth; the number of time steps required to perform the circuit.
Quick start
The following graph provides loose guidelines to help you get started with choosing hardware for your simulation. The qubit upper bounds in this chart are not technical limits.
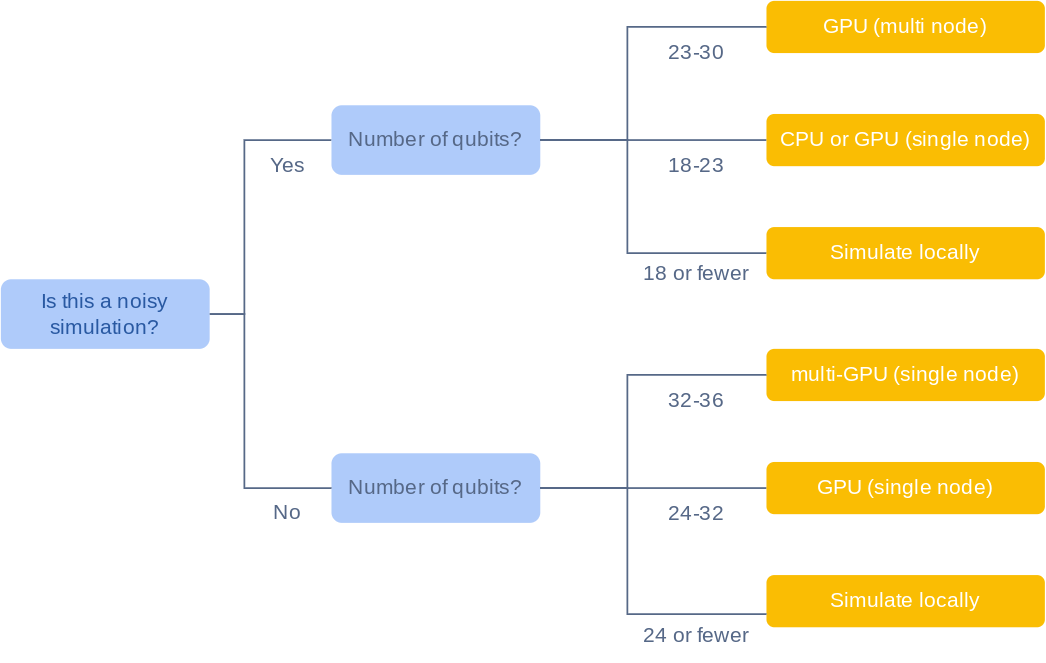
Choose hardware for your simulation
1. Evaluate whether your simulation can be run locally
If you have a modern laptop with at least 8GB of memory, you can run your simulation locally in the following cases:
- Noiseless simulations that use fewer than 29 qubits.
- Noisy simulations that use fewer than 18 qubits.
If you intend to simulate a circuit many times, consider multinode simulation. For more information about multinode simulation see step 5, below.
2. Estimate your memory requirements
You can estimate your memory requirements with the following rule of thumb: \({\rm memory\ required} = 8 \cdot 2^N \ {\rm bytes}\) for an N-qubit circuit
In addition to memory size, consider the bandwidth of your memory. qsim performs best when it can use the maximum number of threads. Multi-threaded simulation benefits from high-bandwidth memory (above 100GB/s).
3. Decide among CPUs, single GPUs, or multiple GPUs
- GPU hardware starts to outperform CPU hardware significantly (up to 15x faster) for circuits with more than 20 qubits.
- The maximum number of qubits that you can simulate with a GPU is limited by the memory of the GPU. For example, for a noiseless simulation on an NVIDIA A100 GPU with 40GB of memory, the maximum number of qubits is 32.
- However, if you have access to a device with multiple GPUs, you can pool their memory. For example, with eight 80-GB NVIDIA A100 GPUs (640GB of total GPU memory), you can simulate up to 36 qubits. Multi-GPU simulations are supported by NVIDIA's cuQuantum Appliance, which acts as a backend for qsim.
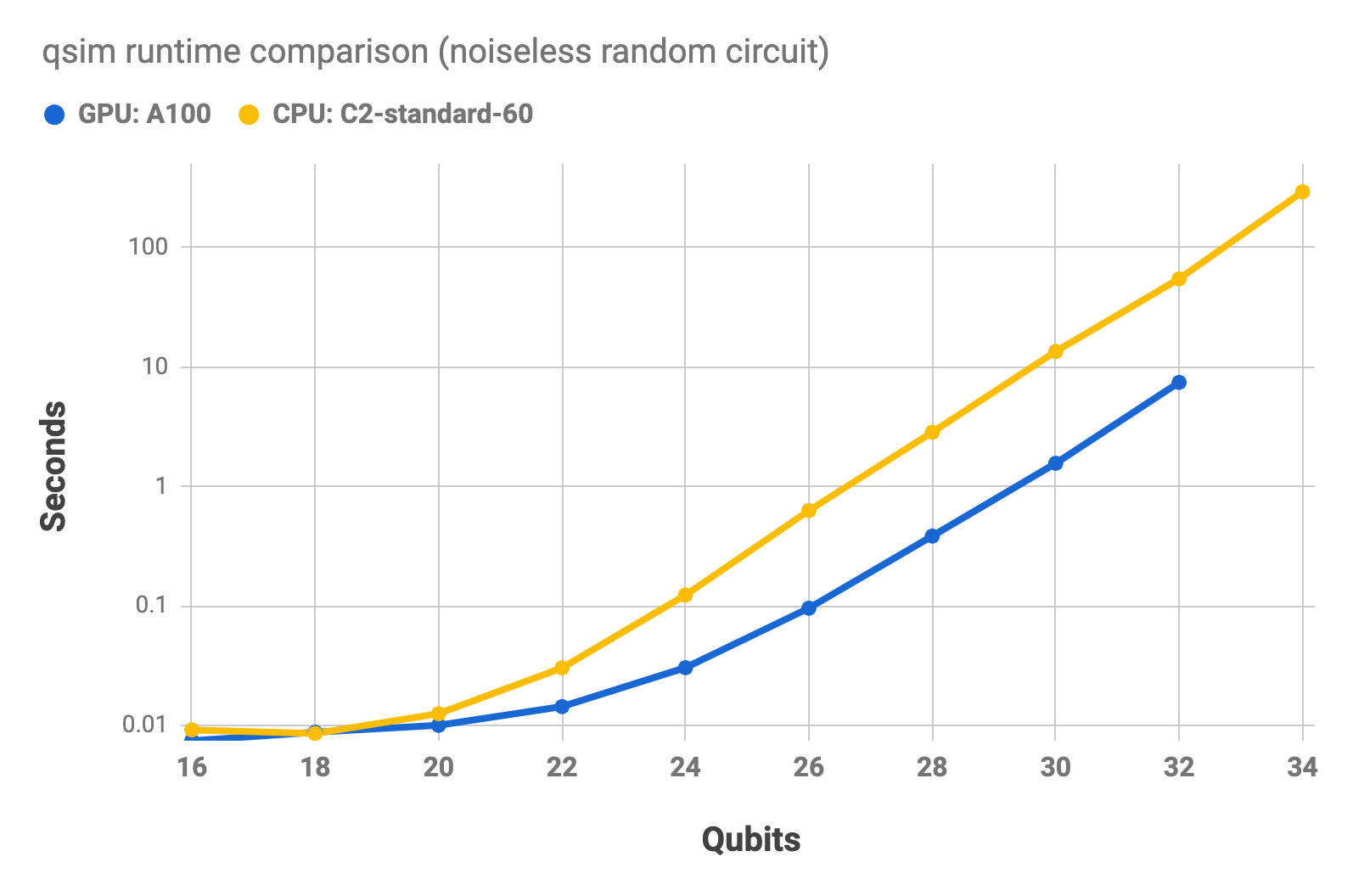
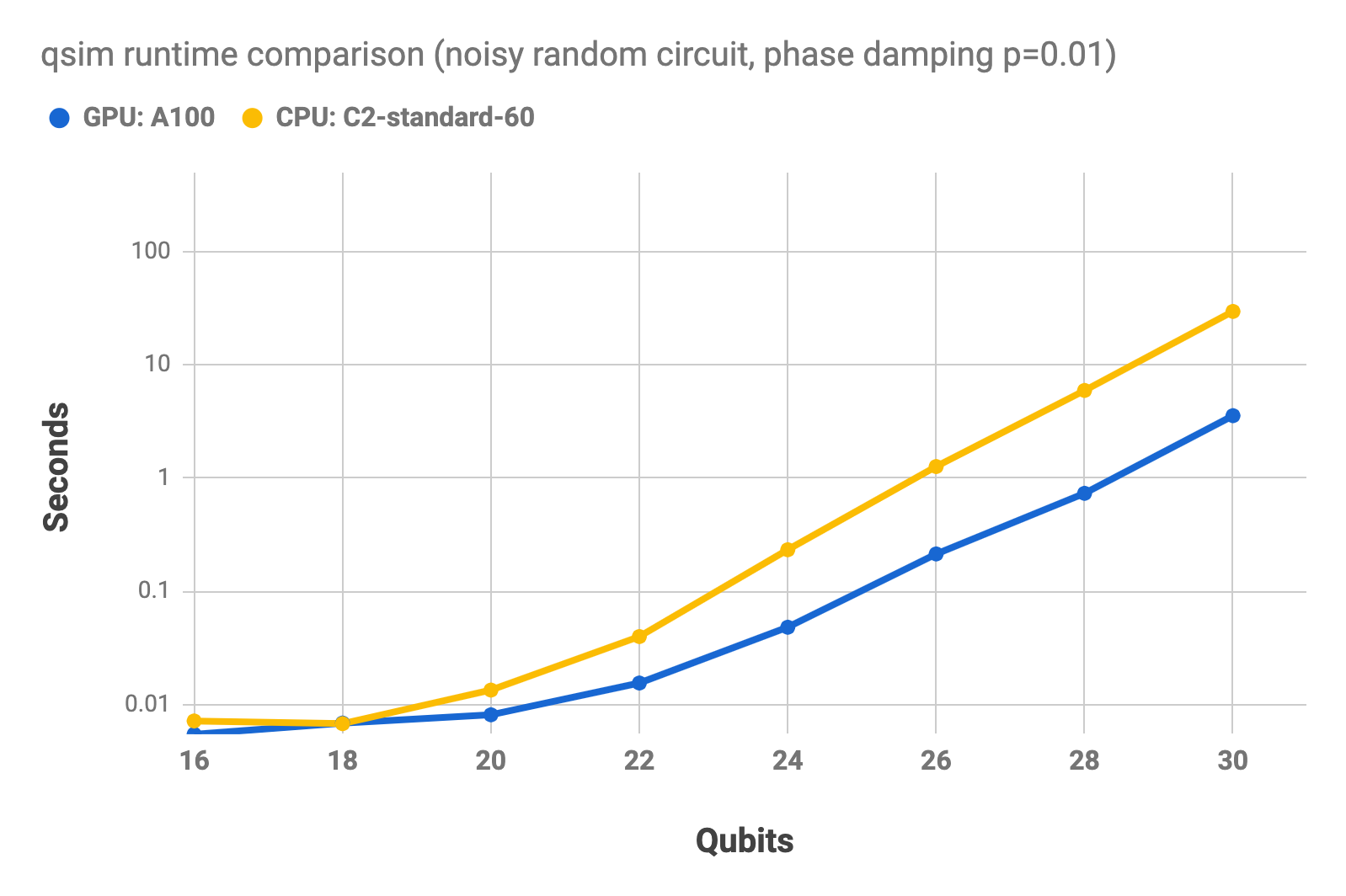
The following charts show the runtime for a random circuit run on Google Compute Engine, using an NVIDIA A100 GPU, and a compute-optimized CPU (c2-standard-4). The first chart shows the runtimes for the noiseless simulation. The second chart shows the runtimes for a noisy simulation, using a phase damping channel (p=0.01). The charts use a log scale. These benchmarks were all performed using qsim's native GPU and CPU backends and do not involve sampling bitstrings (i.e. no measure gates).
4. If using GPUs, select a backend
For GPU-based simulations, you can either use qsim's native GPU backend or the NVIDIA cuQuantum backend. While the native qsim GPU backend is performant for extracting amplitudes of specific quantum states, it is not optimized for sampling bitstrings, i.e., for simulating circuits that have measurement gates. For that purpose, cuQuantum performs significantly better. cuQuantum is also needed for multi-GPU support. More specifically, there are three options for GPU-based simulations:
- Native qsim. This option involves compiling qsim locally with the CUDA toolkit installed, as described here.
- NVIDIA cuQuantum SDK/cuStateVec. This option involves installing NVIDIA's cuQuantum SDK
(instructions here),
setting the
CUQUANTUM_ROOTenvironment variable and then compiling qsim locally. See further instructions here. This allows you to use the cuQuantum backend with the latest version of qsim. However, it does not enable multi-GPU support. - For multi-GPU support, you will need to use cuQuantum Appliance, which runs in a Docker container and contains a version of qsim that has been slightly modified by NVIDIA. The versions of qsim and cirq in this container may be out of date.
We recommend option 2 if you are not planning to run multi-GPU simulations and option 3 if you are.
Note the settings in qsimcirq.QSimOptions,
which allow you to specify the GPU backend as well as related settings. We find
that max_fused_gate_size = 4 is usually optimal for larger circuits, although you may want to experiment yourself.
In cuQuantum Appliance, these settings are extended, as documented here,
allowing you to specify how many and which GPUs to use.
5. Select a specific machine
After you decide whether you want to use CPUs or GPUs for your simulation, choose a specific machine:
For CPU-based simulations:
- Restrict your options to machines that meet your memory requirements. For more information about memory requirements, see step 2.
- Decide if performance (speed) or cost is more important to you:
- For a table of performance benchmarks, see Sample benchmarks below.
- For more information about GCP pricing, see the Google Cloud pricing calculator.
- Prioritizing performance is particularly important in the following
scenarios:
- Simulating with a higher f value (f is the maximum number of
qubits allowed per fused gate).
- For small to medium size circuits (up to 22 qubits), keep f low (2 or 3).
- For medium to large size qubits (22+ qubits), use a higher f typically, f=4 is the best option).
- Simulating a deep circuit (depth 30+).
- Simulating with a higher f value (f is the maximum number of
qubits allowed per fused gate).
For GPU-based simulations:
For GPU simulations, you may follow the instructions in this guide to set up a virtual machine (VM) on Google Cloud Platform (GCP). Alternatively, you can use your own hardware. Note the hardware requirements for NVIDIA's cuQuantum when picking a GPU; in particular, it must have CUDA Compute Capability 7.0 or higher. At the time of writing, the following compatible GPUs are available on GCP:
- NVIDIA T4. This is the least expensive compatible GPU on GCP. It has 16GB of memory and can therefore simulate up to 30 qubits. It is not compatible with multi-GPU simulations.
- NVIDIA V100. Like the NVIDIA T4, this GPU has 16GB of RAM and therefore supports up to 30 qubits. It is faster than the T4. Further, it is compatible with multi-GPU simulations. With 4 NVIDIA V100s (64GB), you can simulate up to 32 qubits.
- NVIDIA L4. This GPU has 24GB of RAM and can therefore simulate up to 31 qubits. With eight of them (192GB), you can simulate up to 34 qubits.
- NVIDIA A100 (40GB). Can simulate 32 qubits with a single GPU or 36 qubits with 16 GPUS (640GB).
- NVIDIA A100 (80GB). Can simulate 33 qubits with a single GPU or 36 with 8 GPUs (640GB).
If you are using GCP, pay attention to the hourly cost, which you can see when creating a VM. To estimate
your total cost, you need to know how long your simulation will take to run. Here
are our benchmarks of the various GPUs (except the L4, which was added after we performed
the benchmarks). We report the time in seconds to run a noiseless depth-N circuit on N qubits and
sample 100,000 N-bit bitstrings, all benchmarked using cuQuantum with max_fused_gate_size = 4.
| GPU | number of GPUs | Runtime using cuQuantum (seconds) | |||||
|---|---|---|---|---|---|---|---|
| N=26 | N=28 | N=30 | N=32 | N=34 | N=36 | ||
| NVIDIA T4 | 1 | 1.25 | 3.5 | 13.4 | insufficient RAM | insufficient RAM | insufficient RAM |
| NVIDIA V100 | 1 | 0.91 | 1.55 | 4.4 | insufficient RAM | insufficient RAM | insufficient RAM |
| NVIDIA V100 | 2 | 1.0 | 1.3 | 2.5 | insufficient RAM | insufficient RAM | insufficient RAM |
| NVIDIA A100 (40GB) | 1 | 0.89 | 1.23 | 2.95 | 11.1 | insufficient RAM | insufficient RAM |
| NVIDIA A100 (40GB) | 2 | 1.04 | 1.24 | 1.88 | 4.85 | insufficient RAM | insufficient RAM |
| NVIDIA A100 (80GB) | 2 | 1.04 | 1.21 | 1.75 | 4.06 | 14.6 | insufficient RAM |
| NVIDIA A100 (80GB) | 8 | 1.31 | 1.38 | 1.55 | 2.23 | 5.09 | 17.6 |
6. Consider multiple compute nodes
Simulating in multinode mode is useful when your simulation can be parallelized. In a noisy simulation, the trajectories (also known as repetitions, iterations) are “embarrassingly parallelizable”, there is an automated workflow for distributing these trajectories over multiple nodes. A simulation of many noiseless circuits can also be distributed over multiple compute nodes.
For more information about running a mulitnode simulation, see Multinode quantum simulation using HTCondor on Google Cloud.
Runtime estimates
Runtime grows exponentially with the number of qubits, and linearly with circuit depth beyond 20 qubits.
- For noiseless simulations, runtime grows at a rate of \(2^N\) for an N-qubit circuit. For more information about runtimes for small circuits, see Additional notes for advanced users below).
- For noisy simulations, runtime grows at a rate of \(2^N\) multiplied by the number of iterations for an N-qubit circuit.
Additional notes for advanced users
- The impact of noise on simulation depends on:
- What type of errors are included in your noise channel (decoherence, depolarizing channels, coherent errors, readout errors).
- How you can represent your noise model using Kraus operator formalism:
- Performance is best in the case where all Kraus operators are proportional to unitary matrices, such as when using only a depolarizing channel.
- Using noise which cannot be represented with Kraus operators proportional to unitary matrices, can slow down simulations by a factor of up to 6** **compared to using a depolarizing channel only
- Noisy simulations are faster with lower noise (when one Kraus operator dominates).
- Experimenting with the 'f' parameter (maximum number of qubits allowed per
fused gate):
- The advanced user is advised to try out multiple f values to optimize
their simulation setup.
- Note that f=2 or f=3 can be optimal for large circuits simulated on CPUs with a smaller number of threads (say, up to four or eight threads). However, this depends on the circuit structure.
- Note that f=6 is very rarely optimal.
- The advanced user is advised to try out multiple f values to optimize
their simulation setup.
- Using the optimal number of threads:
- Use the maximum number of threads on CPUs for the best performance.
- If the maximum number of threads is not used on multi-socket machines then it is advisable to distribute threads evenly to all sockets or to run all threads within a single socket. Separate simulations on each socket can be run simultaneously in the latter case.
- Note that currently the number of CPU threads does not affect the performance for small circuits (smaller than 17 qubits). Only one thread is used because of OpenMP overhead.
- Runtime estimates for small circuits:
- For circuits that contain fewer than 20 qubits, the qsimcirq translation layer performance overhead tends to dominate the runtime estimate. In addition to this, qsim is not optimized for small circuits.
- The total small circuits runtime overhead for an N qubit circuit depends on the circuit depth and on N. The overhead can be large enough to conceal the \(2^N\) growth in runtime.
- The NumPy version matters for large simulations:
- NumPy 1.x defines a constant
NPY_MAXDIMS, which is set to 32 in the NumPy source code. Many internal NumPy structures, such as those for iteration and coordinate tracking, use fixed-size buffers based on this value. Although the C++ core of qsim is not affected by this (since it does not use NumPy), this NumPy limit prevents state vectors from having more than 32 qubits when using Python. Attempting to use 33 or more qubits results in an error. - NumPy 2.x increased this limit to 64 dimensions, and qsim can work with more than 32 qubit when NumPy 2.x is used. If you encounter unexpected failures, memory errors, or hard limits on the number of qubits, ensure you are running a recent NumPy version before further debugging.
- NumPy 1.x defines a constant
Sample benchmarks
The following benchmarks are all run using qsim's native CPU and GPU backends and do not involve sampling bitstrings.
Noiseless simulation benchmarks data sheet
For a random circuit, depth=20, f=3, max threads.
| processor type | machine | # of qubits | runtime |
| CPU | c2-standard-60 | 34 | 291.987 |
| CPU | c2-standard-60 | 32 | 54.558 |
| CPU | c2-standard-60 | 30 | 13.455 |
| CPU | c2-standard-60 | 28 | 2.837 |
| CPU | c2-standard-60 | 24 | 0.123 |
| CPU | c2-standard-60 | 20 | 0.013 |
| CPU | c2-standard-60 | 16 | 0.009 |
| CPU | c2-standard-4-4 | 30 | 52.880 |
| CPU | c2-standard-4-4 | 28 | 12.814 |
| CPU | c2-standard-4-4 | 24 | 0.658 |
| CPU | c2-standard-4-4 | 20 | 0.031 |
| CPU | c2-standard-4-4 | 16 | 0.008 |
| GPU | a100 | 32 | 7.415 |
| GPU | a100 | 30 | 1.561 |
| GPU | a100 | 28 | 0.384 |
| GPU | a100 | 24 | 0.030 |
| GPU | a100 | 20 | 0.010 |
| GPU | a100 | 16 | 0.007 |
| GPU | t4 | 30 | 10.163 |
| GPU | t4 | 28 | 2.394 |
| GPU | t4 | 24 | 0.118 |
| GPU | t4 | 20 | 0.014 |
| GPU | t4 | 16 | 0.007 |
Noisy simulation benchmarks data sheet
For one trajectory of a random circuit, depth=20, f=3, max threads.
| processor type | machine | noise type | # of qubits | runtime |
| CPU | c2-standard-60 | depolarizing | 30 | 13.021 |
| CPU | c2-standard-60 | depolarizing | 28 | 2.840 |
| CPU | c2-standard-60 | depolarizing | 26 | 0.604 |
| CPU | c2-standard-60 | depolarizing | 24 | 0.110 |
| CPU | c2-standard-60 | depolarizing | 20 | 0.009 |
| CPU | c2-standard-60 | depolarizing | 16 | 0.006 |
| CPU | c2-standard-60 | dephasing | 30 | 122.788 |
| CPU | c2-standard-60 | dephasing | 28 | 29.966 |
| CPU | c2-standard-60 | dephasing | 26 | 6.378 |
| CPU | c2-standard-60 | dephasing | 24 | 1.181 |
| CPU | c2-standard-60 | dephasing | 20 | 0.045 |
| CPU | c2-standard-60 | dephasing | 16 | 0.023 |
| CPU | c2-standard-4-4 | depolarizing | 26 | 2.807 |
| CPU | c2-standard-4-4 | depolarizing | 24 | 0.631 |
| CPU | c2-standard-4-4 | depolarizing | 20 | 0.027 |
| CPU | c2-standard-4-4 | depolarizing | 16 | 0.005 |
| CPU | c2-standard-4-4 | dephasing | 26 | 33.038 |
| CPU | c2-standard-4-4 | dephasing | 24 | 7.432 |
| CPU | c2-standard-4-4 | dephasing | 20 | 0.230 |
| CPU | c2-standard-4-4 | dephasing | 16 | 0.014 |
| GPU | a100 | depolarizing | 30 | 1.568 |
| GPU | a100 | depolarizing | 28 | 0.391 |
| GPU | a100 | depolarizing | 26 | 0.094 |
| GPU | a100 | depolarizing | 24 | 0.026 |
| GPU | a100 | depolarizing | 20 | 0.006 |
| GPU | a100 | depolarizing | 16 | 0.004 |
| GPU | a100 | dephasing | 30 | 17.032 |
| GPU | a100 | dephasing | 28 | 3.959 |
| GPU | a100 | dephasing | 26 | 0.896 |
| GPU | a100 | dephasing | 24 | 0.236 |
| GPU | a100 | dephasing | 20 | 0.029 |
| GPU | a100 | dephasing | 16 | 0.021 |
| GPU | t4 | depolarizing | 30 | 10.229 |
| GPU | t4 | depolarizing | 28 | 2.444 |
| GPU | t4 | depolarizing | 26 | 0.519 |
| GPU | t4 | depolarizing | 24 | 0.115 |
| GPU | t4 | depolarizing | 20 | 0.009 |
| GPU | t4 | depolarizing | 16 | 0.004 |
| GPU | t4 | dephasing | 28 | 21.800 |
| GPU | t4 | dephasing | 26 | 5.056 |
| GPU | t4 | dephasing | 24 | 1.164 |
| GPU | t4 | dephasing | 20 | 0.077 |
| GPU | t4 | dephasing | 16 | 0.017 |